Welcome to the world of Social Network Analysis (SNA) in Digital Humanities! In this chapter, we’ll explore how to analyze and visualize relationships between entities in textual data.
Learning Objectives
🕸️ Understand core concepts of social network analysis
🔍 Learn key network metrics and their interpretations
💻 Implement network analysis with R
📊 Create network visualizations
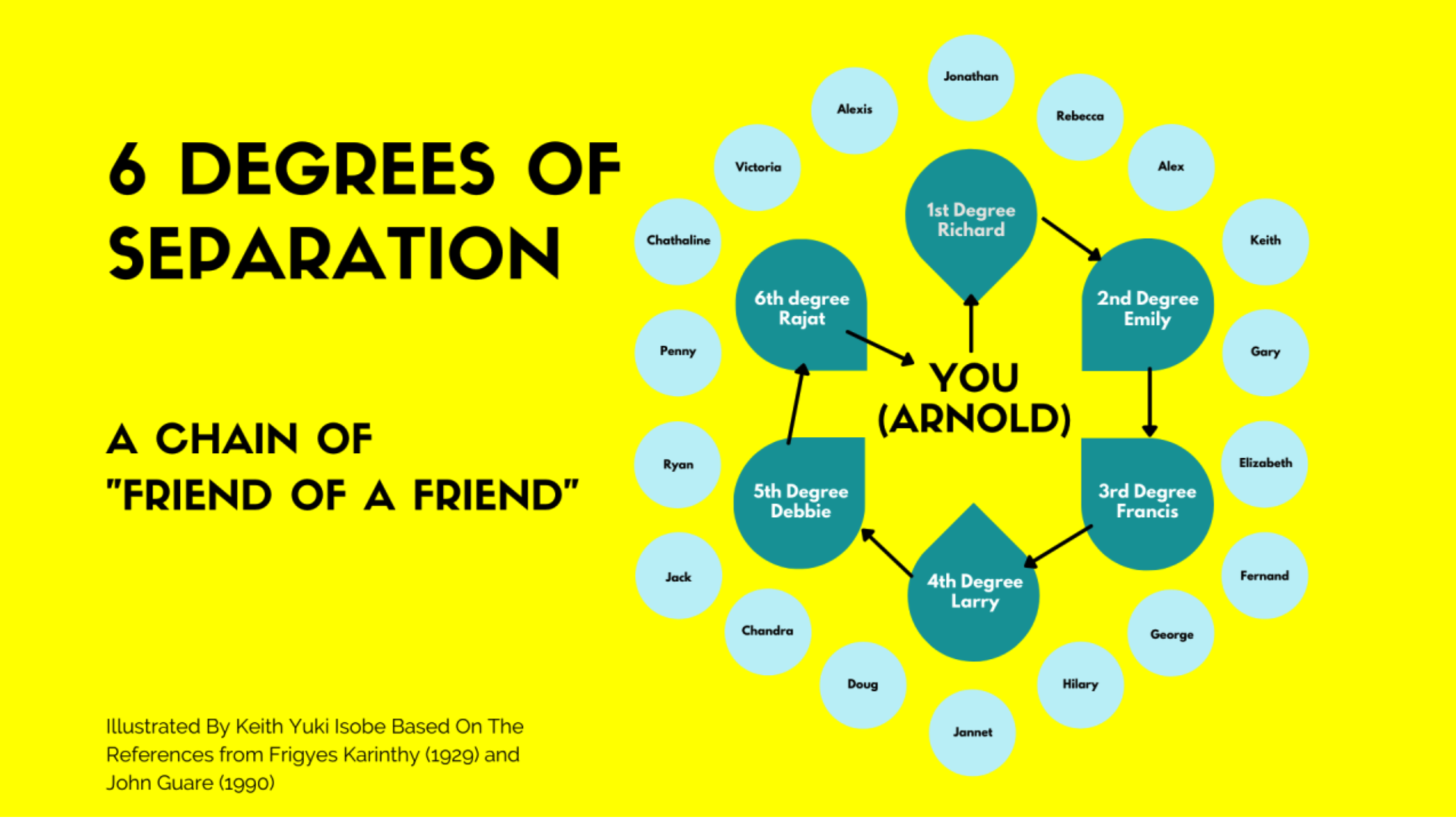
1 Warming Up: Six Degrees of Separation 👥
Have you ever had that surprising moment when you meet someone new and discover you have a mutual friend? Or perhaps you’ve been traveling abroad and bumped into someone who knows your cousin? These aren’t just coincidences - they’re demonstrations of how remarkably interconnected our social world really is!
The Six Degrees Theory
The concept of “six degrees of separation” suggests that any two people on Earth are connected through a chain of no more than six social connections. In other words, you are likely connected to anyone in the world - from a coffee farmer in Ethiopia to a tech entrepreneur in Silicon Valley - through just six or fewer intermediary relationships!
This fascinating idea was first proposed in 1929 when Hungarian author Frigyes Karinthy noted how technology and travel were making the world feel increasingly “smaller” and more interconnected.
Small World Experiment
Stanley Milgram’s groundbreaking experiments in the 1960s examined social network path lengths in the United States
The experiment involved sending packets between random “starter” participants in Nebraska/Kansas to a target in Boston
Key findings:
Average chain length was around 5.5-6 connections
Successful packets often quickly reached geographic proximity of target
Final connections typically came through the target’s close social circle
Modern research shows even shorter paths:
Facebook users are separated by only 3.5 degrees on average
Digital networks have made the world even “smaller”
Though the phrase “six degrees of separation” is commonly associated with the experiment, Milgram never used this term himself
Let’s put the “six degrees of separation” theory to the test! Below is an interactive game where we can explore the social connections between students in our Introduction to Digital Humanities course. Try to find the shortest path between any two students - can they be connected in six steps or fewer? This game will help us understand how social networks work in practice before we dive deeper into network analysis concepts.
Class Network Game
Six Degrees of Separation
Find connections between two random classmates! Each connection represents a shared experience
or relationship. Can the two students be connected in 6 steps or fewer?
Note: Being in the "Intro to DH" class together doesn't count as a connection!
Connect:
刘伯宇 ➔
刘潇晗
Degrees of Separation: 0/6
Search for a student...
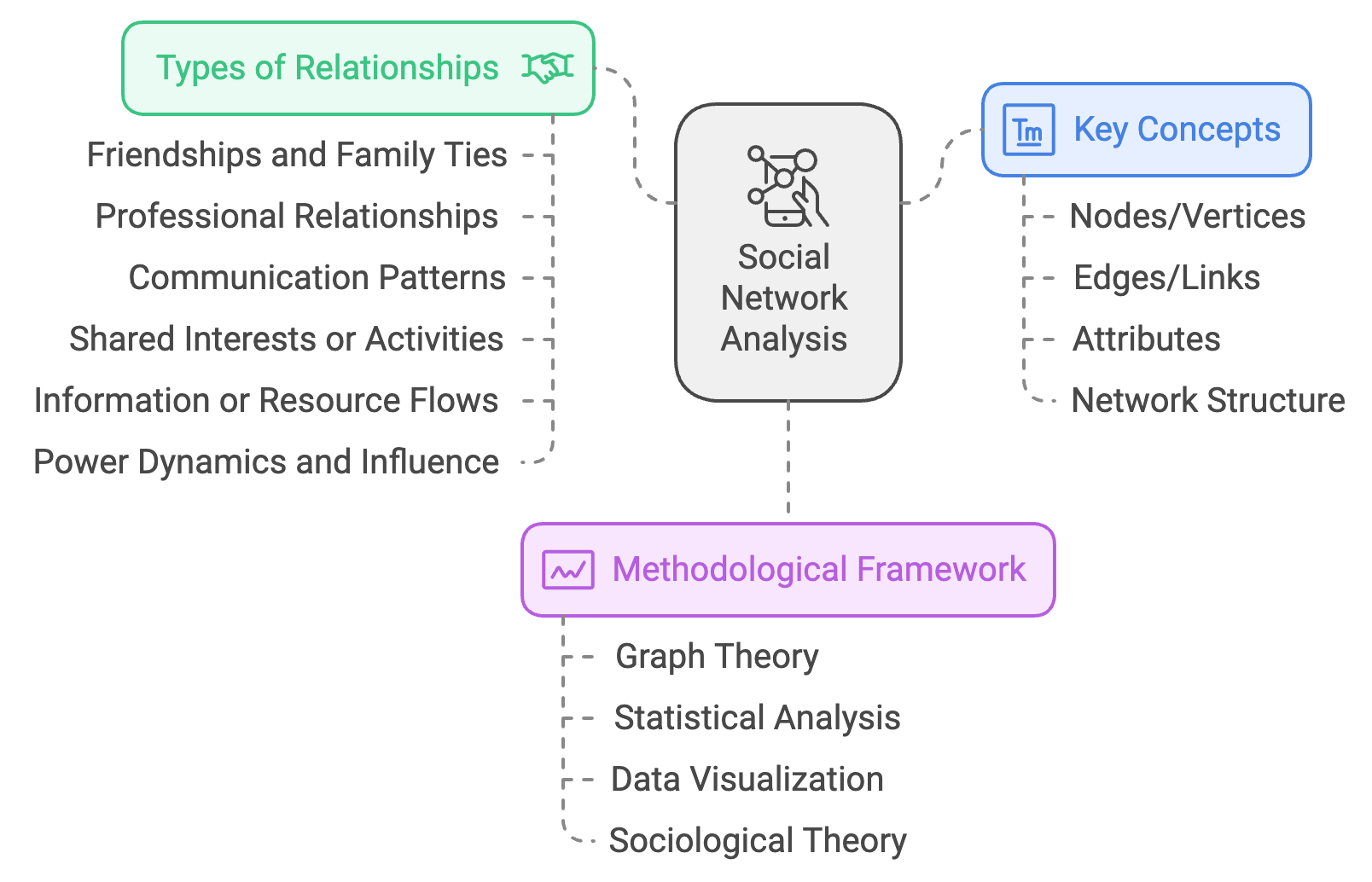
2 What is Social Network Analysis? 🕸️
A social network is a structure made up of social actors (individuals, groups, or organizations) and the connections between them. These connections can represent various types of relationships such as:
Friendships and family ties
Professional relationships
Communication patterns
Shared interests or activities
Information or resource flows
Power dynamics and influence
Social Network Analysis (SNA) is a methodological framework and set of techniques used to study these networks systematically. It combines elements from:
Graph theory
Statistical analysis
Data visualization
Sociological theory
Key Concepts
Nodes/Vertices: The entities in your network (people, organizations, etc.)
Edges/Links: The connections between entities
Attributes: Properties of nodes (e.g., age, gender) or edges (e.g., relationship type, strength)
Network Structure: Overall patterns of connections
What SNA Helps Us Understand
Relationship Patterns
How are different actors connected?
What are the dominant patterns of interaction?
Where are the gaps or clusters in the network?
Power and Influence
Who are the key players?
How does information or resources flow?
Who controls access to different parts of the network?
Community Structure
What subgroups exist?
How do different communities interact?
Where are the boundaries between groups?
Network Evolution
How do networks change over time?
What factors affect network formation?
How do disruptions impact the network?
3 Core Concepts in Network Analysis 🎯
3.1 Types of Network
Understanding Different Network Types 🔄
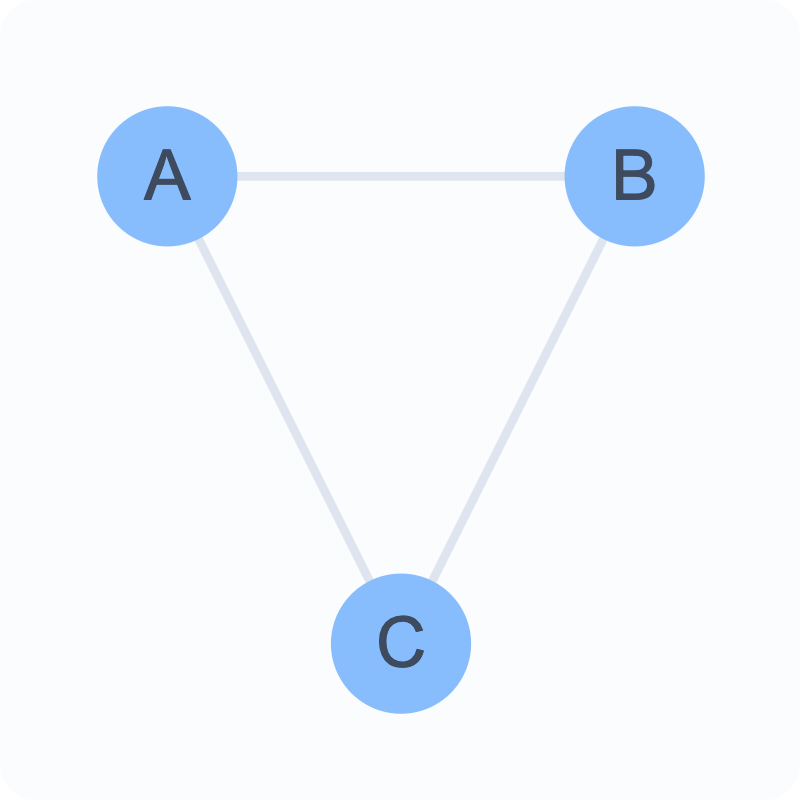
Undirected Networks ↔︎️
Connections work both ways
If A is connected to B, B is connected to A
Example: Facebook friendships
Represented by simple lines between nodes
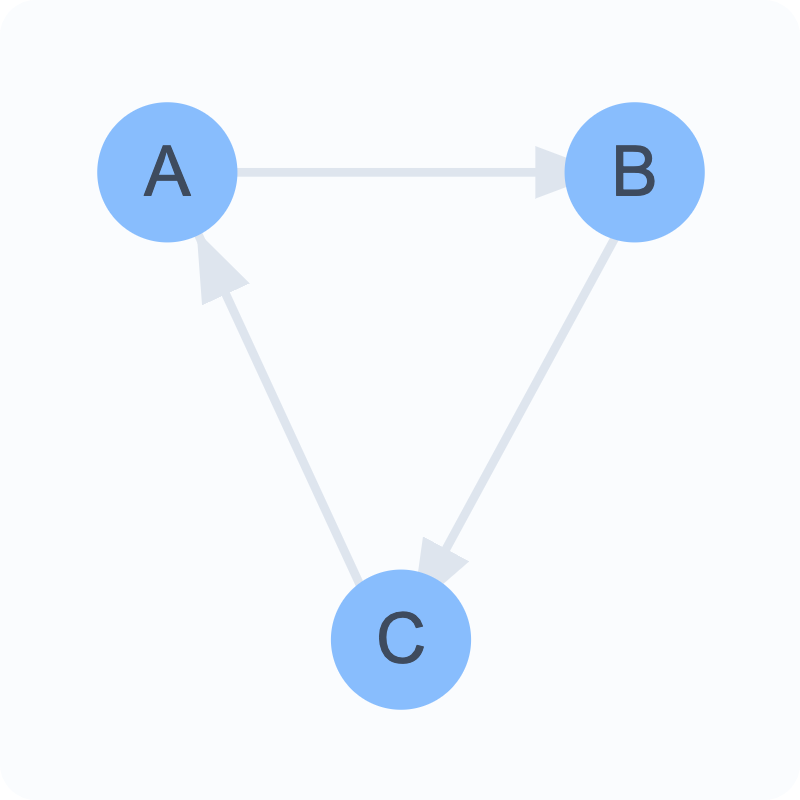
Directed Networks ➡️
Connections have a specific direction
A can connect to B without B connecting to A
Example: Twitter followers
Represented by arrows showing direction
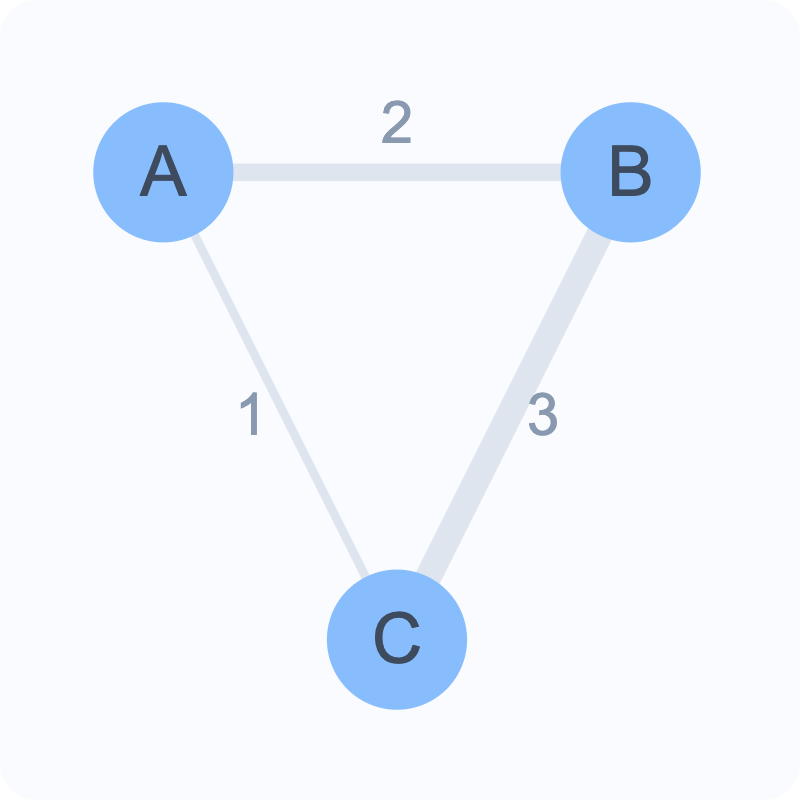
Weighted Networks 📊
Connections have different strengths
Example: Number of interactions between characters
Represented by different line thicknesses
Other network types include:
Bipartite Networks: Two node types with connections only between different types (e.g., authors-papers)
Multiplex Networks: Multiple relationship types between same nodes (e.g., friends/enemies)
3.2 Understanding Important Nodes
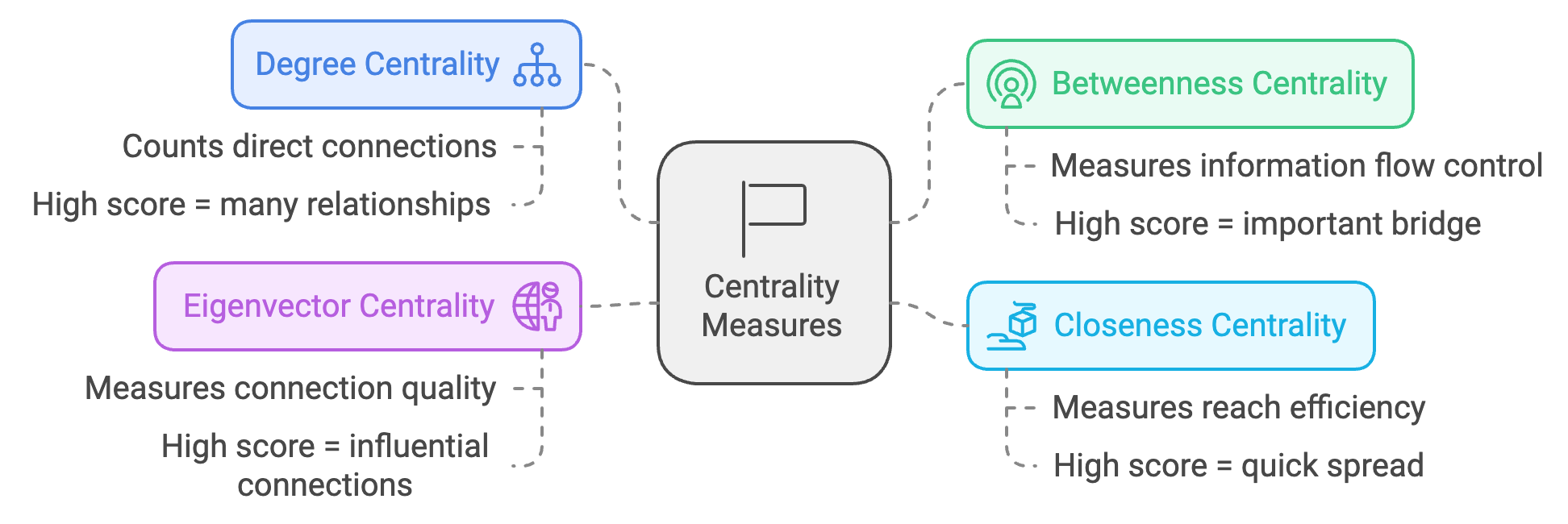
Let’s explore the four most important ways to measure importance in a network: centrality. Centrality measures help us identify the most important or influential nodes in a network. Think of it like finding the “key players” in a social group.
What Makes Someone “Important” in a Network? 🤔
Think about your own social circles and consider these questions:
Who knows the most people? (The people person 💫)
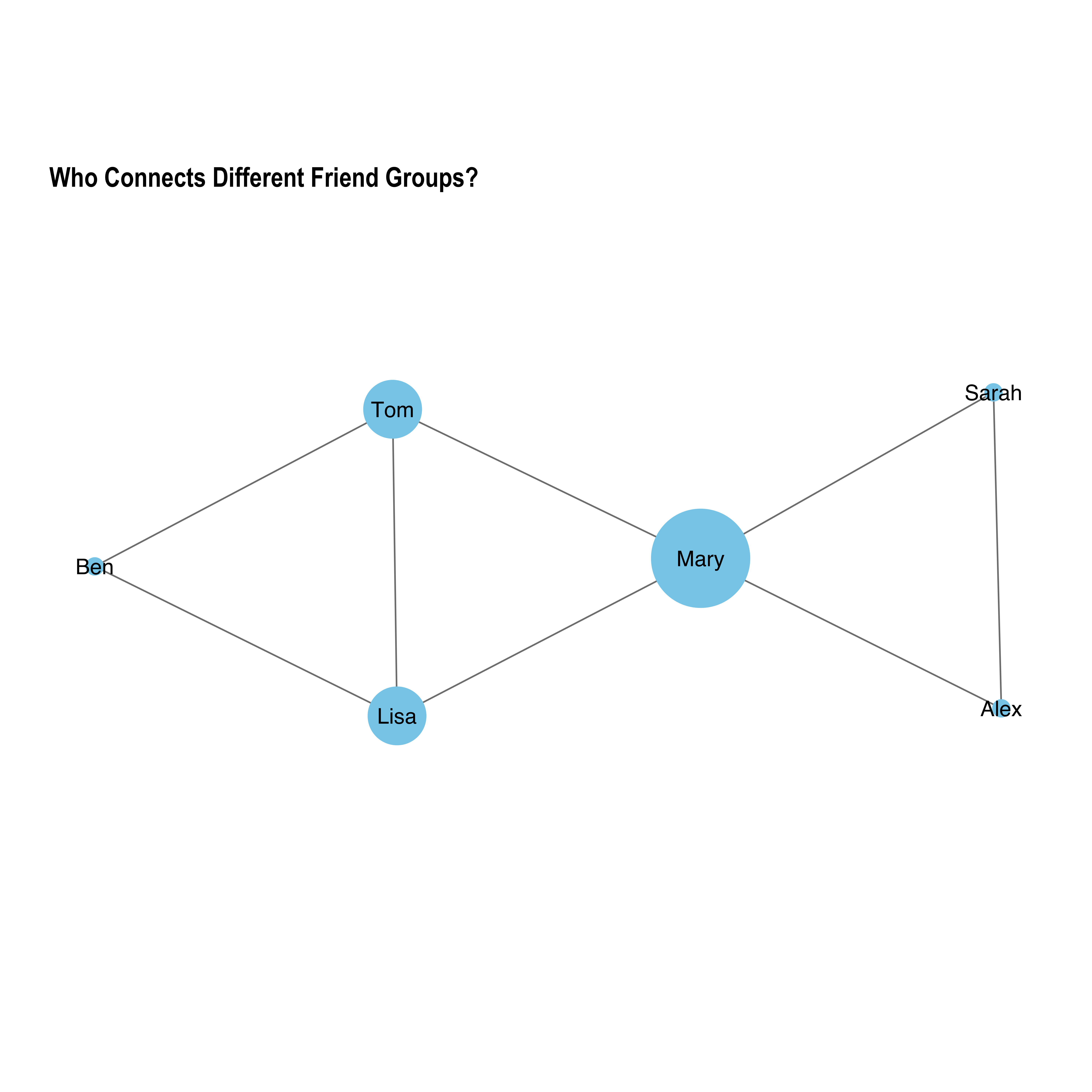
Who connects different friend groups together? (The bridge builder 🌉)
Who can spread news the fastest? (The information hub 📢)
Who hangs out with all the popular people? (The well-connected 🌟)
Take a moment to think about specific people in your life who fit these roles!
Four Ways to Be “Important”
Degree Centrality: The “Popular” Nodes 👥
Counts direct connections
Like counting your friends
High score = lots of direct relationships
Betweenness Centrality: The “Bridge” Nodes 🌉
Measures information flow control
Like being the only connection between groups
High score = important for connecting others
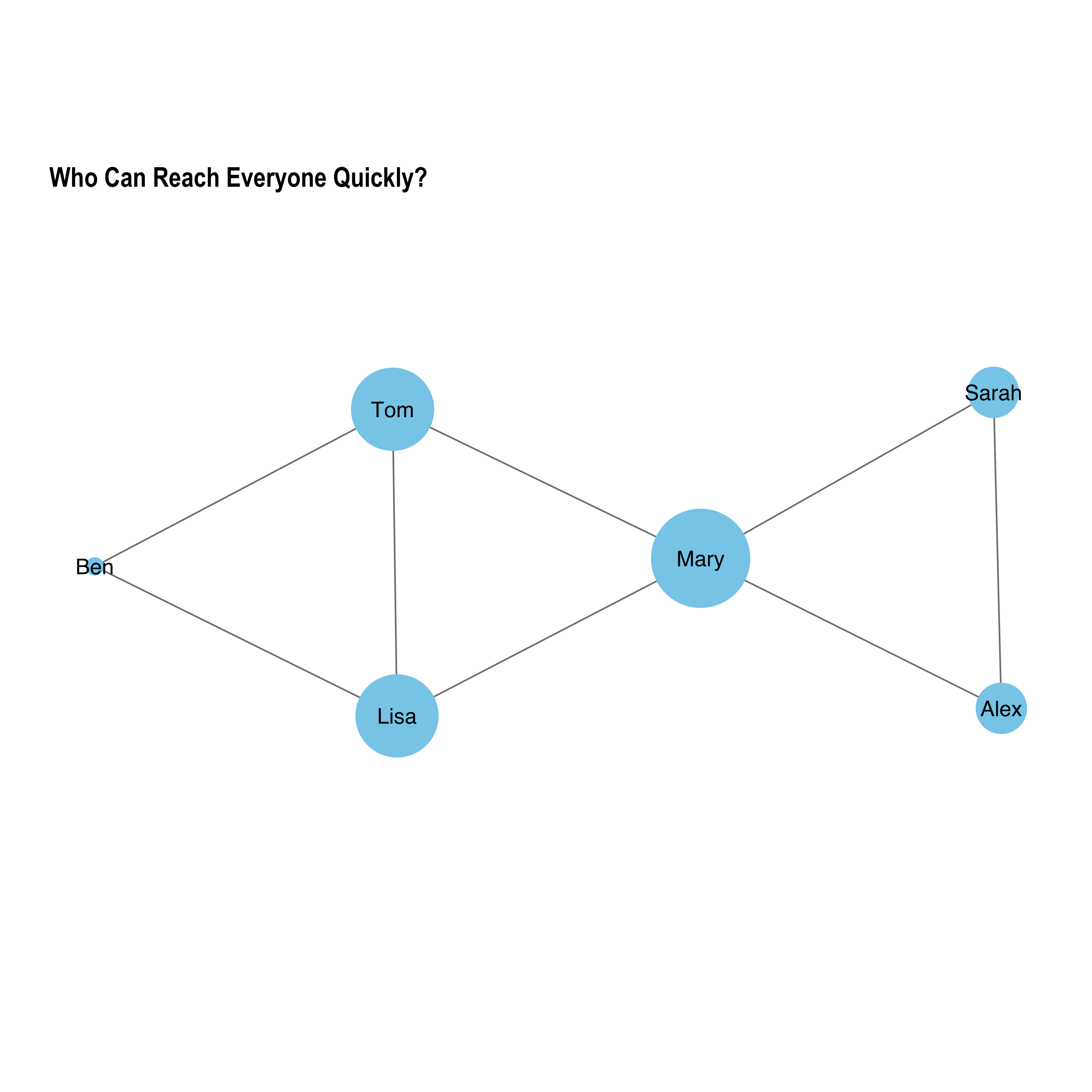
Closeness Centrality: The “Efficient” Nodes 🎯
Measures how quickly a node can reach others
Like being in the center of the network
High score = can spread information quickly
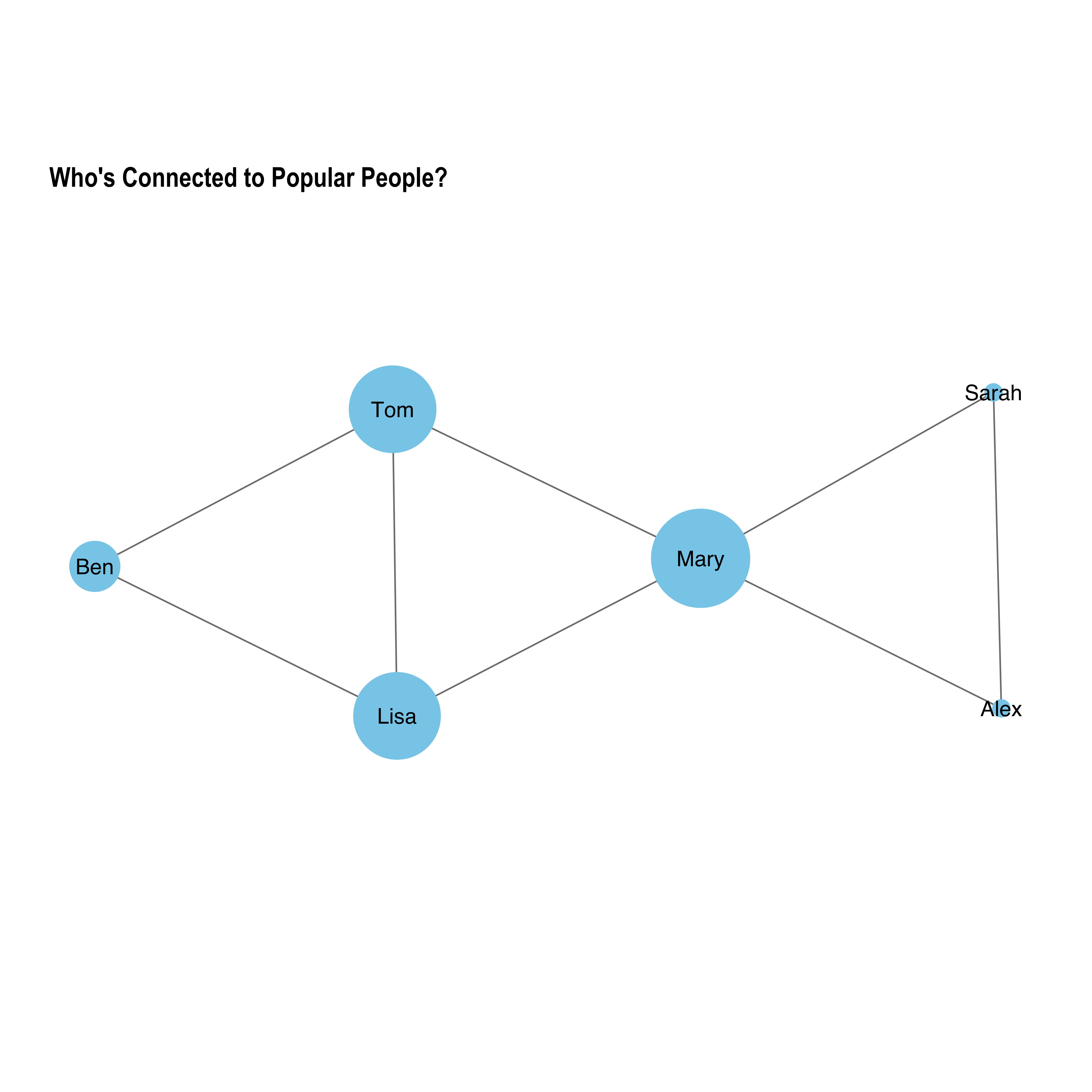
Eigenvector Centrality: The “Well-Connected” Nodes ⭐
Measures connection quality
Like having influential friends
High score = connected to important nodes
3.3 A Friendship Network
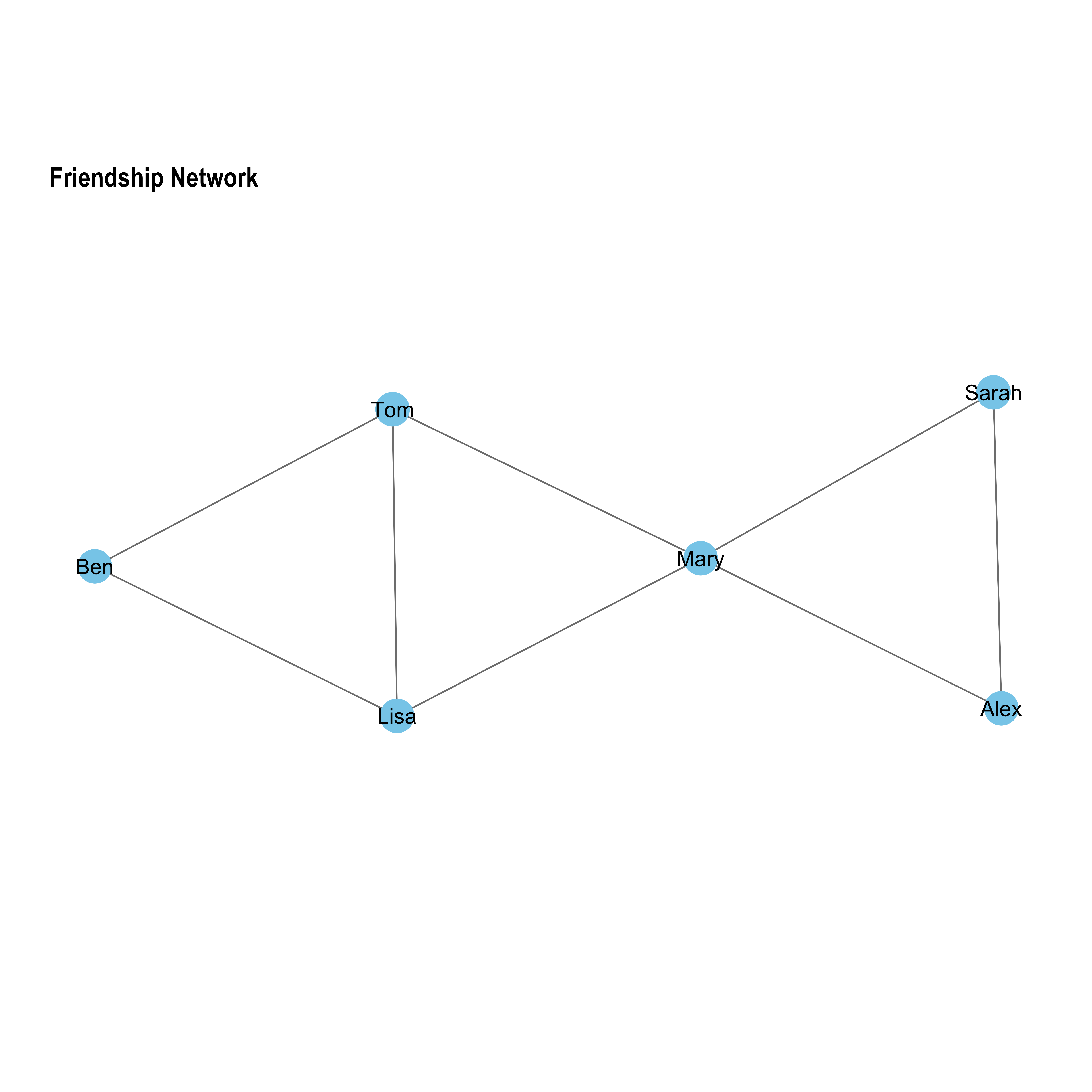
Let’s take a look at a mock friendship network to understand how centrality metrics work in their simplest form - through counting! Let’s first draw the friendship network.
# Load librarieslibrary(pacman)p_load(tidyverse,tidygraph,ggraph)# 1. Create Nodes and Edges# Define the nodes (friends)nodes<-tibble(name =c("Mary", "Alex", "Sarah", "Tom", "Lisa", "Ben"))# Define the edges (friendships)edges<-tribble(~from, ~to,"Mary", "Alex","Mary", "Sarah","Alex", "Sarah","Mary", "Tom","Mary", "Lisa","Tom", "Lisa","Lisa", "Ben","Tom", "Ben")# 2. Create a Graph Objectgraph<-tbl_graph(nodes =nodes, edges =edges, directed =FALSE)# 3. Plot the Network with Equal Node Sizesset.seed(1234)ggraph(graph, layout ="auto")+# 'auto' chooses best layout algorithm for network size/typegeom_edge_link(color ="grey50")+# Draw edgesgeom_node_point(size =10, color ="skyblue")+# Draw nodesgeom_node_text(aes(label =name), size =5)+# Add labelstheme_graph()+coord_fixed()+# Keep aspect ratio fixed as equal to avoid stretchingexpand_limits(x =c(-1, 1), y =c(-1, 1))+ggtitle("Friendship Network")
3.3.1 🤔 Understanding Centrality: Let’s Count!
Before we let computers do the heavy lifting, let’s practice counting these metrics ourselves! This will help us truly understand what these measurements mean. Below are some basic counting principles:
Degree Centrality: Simply count direct friends
Betweenness Centrality: Count how many times someone is on the shortest path between others
Closeness Centrality: Count minimum steps needed to reach everyone else
Eigenvector Centrality: Count connections, but give extra points for popular friends
1. The "Popular" Score (Degree Centrality)
Simply count direct friends
Mary has friends
Ben has friends
2. The "Bridge Builder" Score (Path Length)
Count the minimum steps needed to get from one person to another through friends
Shortest path from Ben to Sarah takes steps
3. The "Efficient" Score (Closeness Centrality)
Count the total number of steps needed to reach everyone else in the network
Total steps for Mary to reach everyone:
4. The "Well-Connected" Score (Eigenvector Centrality)
Scoring method:
1. Base score: Count 1 point for each direct friend
2. Bonus score: For each friend, add 0.5 points for each additional connection that friend has (excluding the connection back to the node being scored)
Tom's score: points
Alex's score: points
This hands-on counting exercise shows us how centrality metrics work at their core. Now that we understand the basic principles, let’s use R to calculate these metrics for the entire network.
# 4. Calculate Centrality Metricsgraph<-graph%>%activate(nodes)%>%# Activate the nodes component for subsequent calculationmutate( degree =centrality_degree(), closeness =centrality_closeness(), betweenness =centrality_betweenness(), eigenvector =centrality_eigen())# View the centrality metricsgraph%>%as_tibble()%>%select(name, degree, closeness, betweenness, eigenvector)
# A tibble: 6 × 5
name degree closeness betweenness eigenvector
<chr> <dbl> <dbl> <dbl> <dbl>
1 Mary 4 0.167 6 1
2 Alex 2 0.111 0 0.543
3 Sarah 2 0.111 0 0.543
4 Tom 3 0.143 1.5 0.878
5 Lisa 3 0.143 1.5 0.878
6 Ben 2 0.1 0 0.618
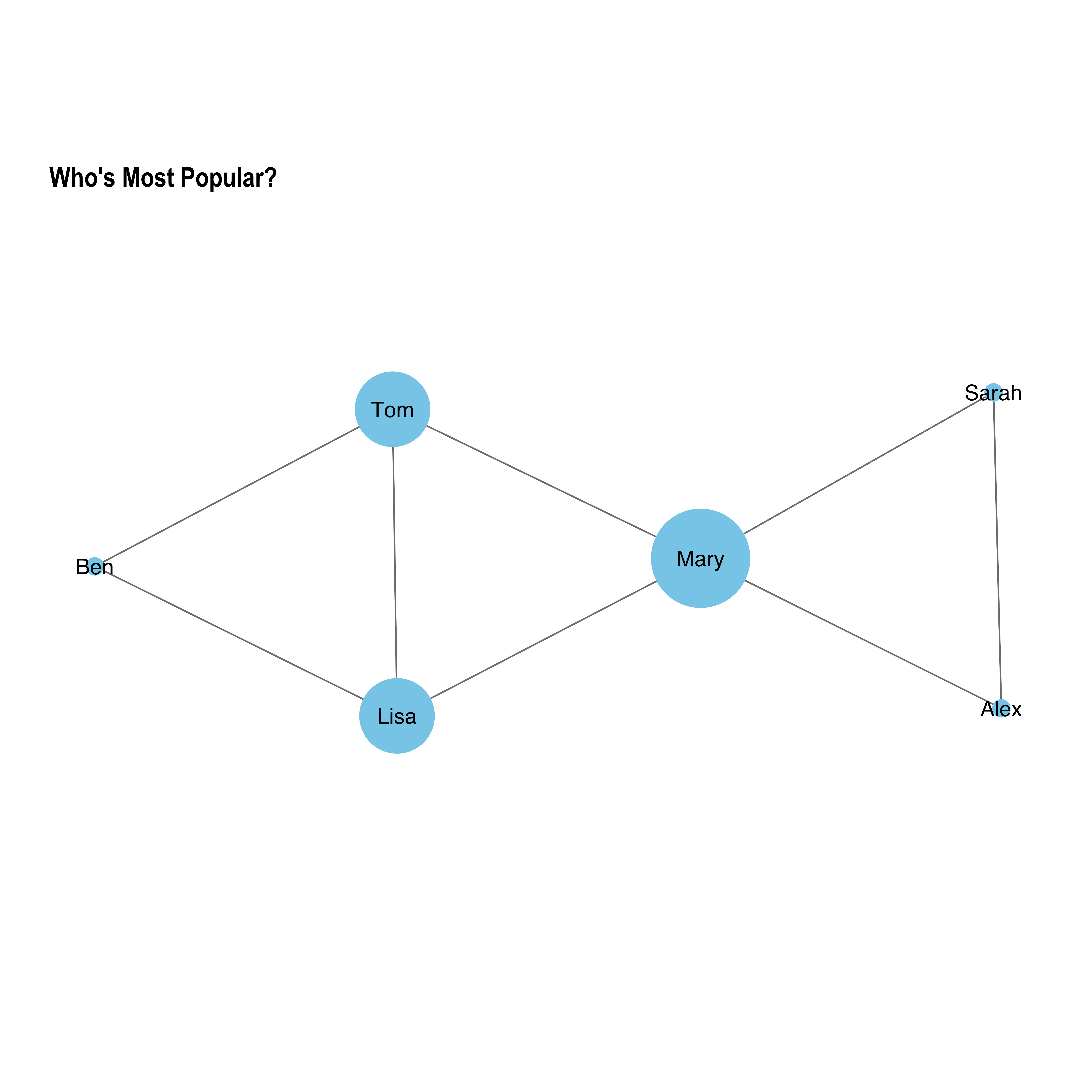
# 5. Function to Plot Network with Variable Node Sizesplot_centrality<-function(graph, centrality_metric, title){set.seed(1234)ggraph(graph, layout ="auto")+geom_edge_link(color ="grey50")+# Draw edgesgeom_node_point(aes(size =!!sym(centrality_metric)), color ="skyblue")+# Vary node sizesgeom_node_text(aes(label =name), size =5, family ="sans")+# Add labelstheme_graph()+coord_fixed()+# Keep aspect ratio fixed as equal to avoid stretchingexpand_limits(x =c(-1, 1), y =c(-1, 1))+scale_size_continuous(range =c(5, 30))+# Adjust node size rangeggtitle(title)+theme(legend.position ="none", text =element_text(family ="sans"))}# 6. Plot Networks with Varying Node Sizes Based on Centrality Metricsplot_centrality(graph, "degree", "Who's Most Popular?")
plot_centrality(graph, "betweenness", "Who Connects Different Friend Groups?")
plot_centrality(graph, "closeness", "Who Can Reach Everyone Quickly?")
plot_centrality(graph, "eigenvector", "Who's Connected to Popular People?")
4 Implementing Network Analysis with R 💻
4.1 Case 1: Character Networks in “Empresses in the Palace”
Let’s analyze the complex relationships in the Chinese drama “Empresses in the Palace”.
JSON (JavaScript Object Notation) is a lightweight data format that’s easy for both humans to read and machines to process. Think of it like a shopping list with organized sections:
It uses { } curly braces to define objects (like containers)
It uses [ ] square brackets for arrays (lists of items)
Data is stored as “key”: “value” pairs (like “name”: “甄嬛”)
To analyze relationships between characters, we need to create a specialized graph structure that represents:
Characters (nodes/vertices)
Their relationships (edges/links) if the links have directions, then we need to specify:
source: where the arrow starts
target: where the arrow points to
Properties of both characters (node/vertice attributes) and relationships (edge/link attributes)
# Load required packageslibrary(pacman)p_load(tidyverse, igraph, # for graph visualization and analysisggraph, # for graph visualizationshowtext, # enable use of custom fonts for Chineseggrepel, # prevent text label overlapcowplot, # theme layout for multiple plotsjsonlite# for handling json data)# Read the JSON datarelation_data<-jsonlite::fromJSON("data/relation.json")# Process node datarelation_data$nodes<-relation_data$nodes%>%rename(Bio ="角色描述")%>%mutate(Alliance =ifelse(Alliance=="皇后阵容", "皇后阵营", Alliance))# Process edge datarelation_data$edges$source<-as.character(relation_data$edges$source)relation_data$edges$target<-as.character(relation_data$edges$target)relation_data$nodes$ID<-as.character(relation_data$nodes$ID)edges<-relation_data$edges%>%select(-Relationship)# Create the graphempresses_graph<-graph_from_data_frame( d =edges, vertices =relation_data$nodes$ID, directed =TRUE)# Set node attributesV(empresses_graph)$Alliance<-relation_data$nodes$AllianceV(empresses_graph)$Label<-relation_data$nodes$Label# Set edge attributesE(empresses_graph)$Relationship<-relation_data$edges$Relationship
When you print an igraph object, you see information in this format:
IGRAPH 2dff8c8 DN--44133--
Let’s break this down: - 2dff8c8: Unique identifier for the graph - D: Directed graph (would be U for undirected) - N: Named vertices - 44: Number of vertices (nodes) - 133: Number of edges (connections)
v/c: Vertex attributes of character type (can also have numeric data type)
e/c: Edge attributes of character type (can also have numeric data type)
name: Internal vertex names
Alliance, Label: Custom vertex attributes we added
Relationship: Custom edge attributes we added
The edges section:
+ edges from 2dff8c8 (graph ID):[1] 1->21->31->4 ...
Shows connections using vertex IDs/names
Arrow -> indicates direction
Numbers in [] are edge indices
4.1.2 Step 2: Analyzing Network Metrics
So, how are we going to calculate the centrality metrics? Our situation seems more complex in this case as we have a directed network.
Network Centrality Parameters Guide
Degree Centrality
mode="in": Count incoming connections
mode="out": Count outgoing connections
mode="all": Count all connections (undirected)
mode="total": Sum of in + out connections
Betweenness Centrality
directed=TRUE: Path order matters (A→B→C ≠ C→B→A)
directed=FALSE: Path order ignored
weights: NULL for equal paths, or specify weights
Closeness Centrality
mode="out": How quickly node reaches others
mode="in": How quickly others reach node
mode="all": Connections in either direction
normalized=TRUE: Adjust for network size (recommended). A caveat that how to calculate closeness (e.g., regarding disconnected components) is still contested
Eigenvector Centrality
directed=TRUE: Influence flows one way. A→B means A influences B but not vice versa
directed=FALSE: Influence flows both ways. A→B means A and B influence each other
# Load required packageslibrary(pacman)p_load(tidyverse, igraph, ggraph, showtext, ggrepel, cowplot, jsonlite)# Calculate centrality measures and pivot to long format# Now calculate centrality measurescentrality_rankings<-tibble( Character =V(empresses_graph)$Label, Degree =degree(empresses_graph, mode="all"), # counts both in and out Betweenness =betweenness(empresses_graph, directed=FALSE), Closeness =closeness(empresses_graph, mode="all", normalized=TRUE), Eigenvector =eigen_centrality(empresses_graph, directed=FALSE)$vector)%>%pivot_longer( cols =-Character, names_to ="Metric", values_to ="Value")%>%group_by(Metric)%>%slice_max(order_by =Value, n =5)%>%mutate( Metric =case_when(Metric=="Degree"~"Most Connected (Degree)",Metric=="Betweenness"~"Best Brokers (Betweenness)",Metric=="Closeness"~"Most Central (Closeness)",Metric=="Eigenvector"~"Most Influential (Eigenvector)"))# Display resultscentrality_rankings%>%arrange(Metric, desc(Value))%>%group_by(Metric)%>%knitr::kable( caption ="Top 5 Characters by Different Centrality Measures", digits =3)
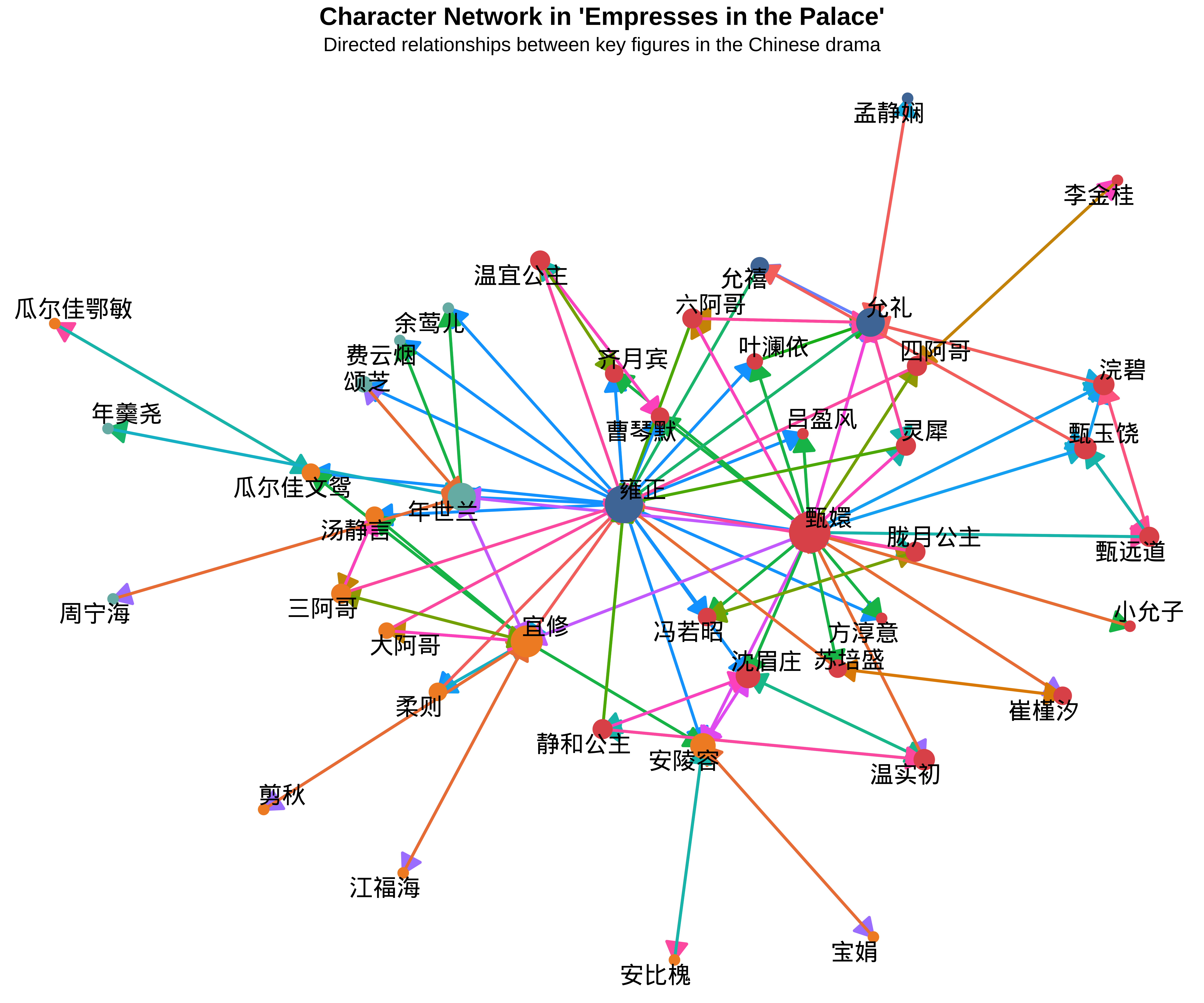
Top 5 Characters by Different Centrality Measures
Character
Metric
Value
雍正
Best Brokers (Betweenness)
387.817
甄嬛
Best Brokers (Betweenness)
358.539
宜修
Best Brokers (Betweenness)
141.290
年世兰
Best Brokers (Betweenness)
102.310
安陵容
Best Brokers (Betweenness)
83.750
雍正
Most Central (Closeness)
0.741
甄嬛
Most Central (Closeness)
0.672
宜修
Most Central (Closeness)
0.558
年世兰
Most Central (Closeness)
0.518
安陵容
Most Central (Closeness)
0.506
甄嬛
Most Connected (Degree)
38.000
雍正
Most Connected (Degree)
31.000
宜修
Most Connected (Degree)
19.000
允礼
Most Connected (Degree)
14.000
年世兰
Most Connected (Degree)
13.000
甄嬛
Most Influential (Eigenvector)
1.000
雍正
Most Influential (Eigenvector)
0.729
宜修
Most Influential (Eigenvector)
0.550
允礼
Most Influential (Eigenvector)
0.508
年世兰
Most Influential (Eigenvector)
0.393
4.1.3 Step 3: Visualizing the Network
Now let’s create a visual representation of these complex relationships. For node size, we will use degree centrality, i.e., the bigger the node, the more connections they have with others. We will also add information about alliances and the nature of relationships into the graph.
# Add Noto Sans CJK fontfont_add_google("Noto Sans SC", "Noto Sans SC")showtext_auto()# Create a color palette for alliancesalliance_colors<-c("皇室成员"="#4E79A7", # Royal Blue"皇后阵营"="#F28E2B", # Warm Orange"甄嬛阵营"="#E15759", # Soft Red"华妃阵营"="#76B7B2"# Teal)# Calculate node size based on total degree centrality V(empresses_graph)$size<-degree(empresses_graph, mode ="all")# Plot the networkset.seed(123)# for reproducibilityplot<-ggraph(empresses_graph, layout ="auto")+geom_edge_link0(aes(edge_color =Relationship), # Color edges based on relationship type arrow =arrow(# Add arrowheads to show direction length =unit(0.2, "inches"), ends ="last", # Arrow only at end of line type ="closed"# Solid arrowhead), show.legend =FALSE, # Hide the relationship legend width =1# Set edge thickness)+geom_node_point(aes(color =Alliance, size =size), shape =20, show.legend =FALSE)+geom_node_text(aes(label =Label), repel =TRUE, size =6)+scale_color_manual(values =alliance_colors)+scale_edge_colour_discrete()+scale_size_continuous(range =c(5, 20))+# Rescale the node size to be more visibletheme_void()+labs(title ="Character Network in 'Empresses in the Palace'", subtitle ="Directed relationships between key figures in the Chinese drama")+theme( plot.title =element_text(hjust =0.5, size =18, face ="bold"), plot.subtitle =element_text(hjust =0.5, size =14),# legend.text = element_text(size = 8),# legend.title = element_text(size = 10, face = "bold"))# Plotplot
4.2 Case 2: Zachary’s Karate Club
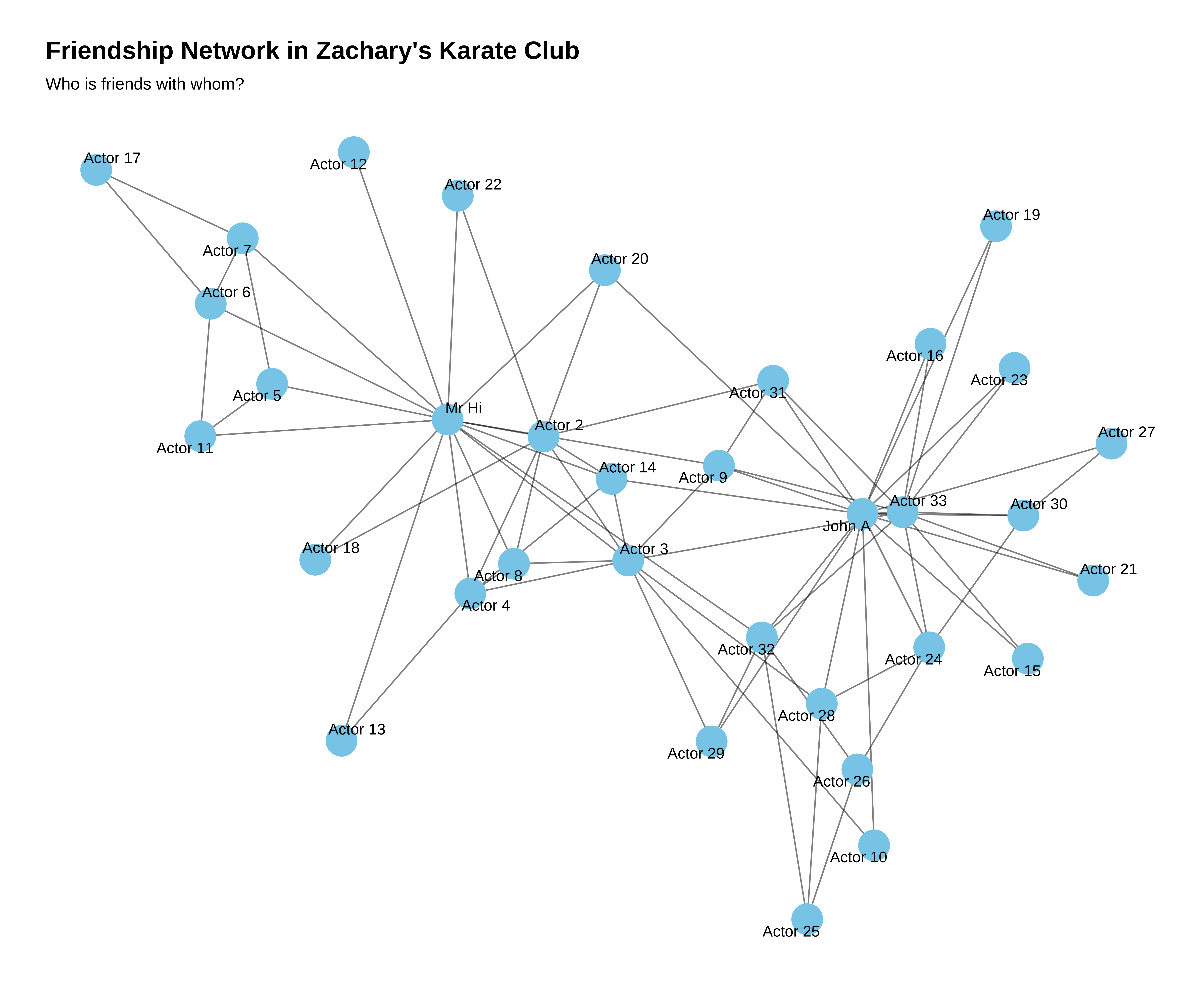
Let’s put our network analysis skills to the test with a fascinating real-world dataset - Zachary’s Karate Club! This is a social network of friendships between 34 members of a karate club at a US university in the 1970s.
The Story Behind the Data
In 1977, Wayne Zachary studied the social network of a university karate club that was on the verge of splitting up. The club faced a conflict between the instructor (Mr. Hi) and the president (John A.). This led to the club dividing into two groups - some members sided with the instructor, others with the president. The network data captured the friendships before the split.
4.3 Step 1: Load and Examine the Network Data
# Load required packageslibrary(pacman)p_load(tidyverse, igraph, ggraph, igraphdata)# Load the karate club network datadata("karate", package ="igraphdata")karate_graph<-upgrade_graph(karate)karate_graph
IGRAPH 4b458a1 UNW- 34 78 -- Zachary's karate club network
+ attr: name (g/c), Citation (g/c), Author (g/c), Faction (v/n), name
| (v/c), label (v/c), color (v/n), weight (e/n)
+ edges from 4b458a1 (vertex names):
[1] Mr Hi --Actor 2 Mr Hi --Actor 3 Mr Hi --Actor 4 Mr Hi --Actor 5
[5] Mr Hi --Actor 6 Mr Hi --Actor 7 Mr Hi --Actor 8 Mr Hi --Actor 9
[9] Mr Hi --Actor 11 Mr Hi --Actor 12 Mr Hi --Actor 13 Mr Hi --Actor 14
[13] Mr Hi --Actor 18 Mr Hi --Actor 20 Mr Hi --Actor 22 Mr Hi --Actor 32
[17] Actor 2--Actor 3 Actor 2--Actor 4 Actor 2--Actor 8 Actor 2--Actor 14
[21] Actor 2--Actor 18 Actor 2--Actor 20 Actor 2--Actor 22 Actor 2--Actor 31
[25] Actor 3--Actor 4 Actor 3--Actor 8 Actor 3--Actor 9 Actor 3--Actor 10
+ ... omitted several edges
About the attributes in the karate dataset
The edge weights are the number of common activities the club members took part of. These activities were:
Association in and between academic classes at the university.
Membership in Mr. Hi’s private karate studio on the east side of the city where Mr. Hi taught nights as a part-time instructor.
Membership in Mr. Hi’s private karate studio on the east side of the city, where many of his supporters worked out on weekends.
Student teaching at the east-side karate studio referred to in (2). This is different from (2) in that student teachers interacted with each other, but were prohibited from interacting with their students.
Interaction at the university rathskeller, located in the same basement as the karate club’s workout area.
Interaction at a student-oriented bar located across the street from the university campus.
Attendance at open karate tournaments held through the area at private karate studios.
Attendance at intercollegiate karate tournaments held at local universities. Since both open and intercollegiate tournaments were held on Saturdays, attendance at both was impossible.
The ‘Faction’ vertex attribute gives the faction memberships of the actors. After the split of the club, club members chose their new clubs based on their factions, except actor no. 9, who was in John A.’s faction but chose Mr. Hi’s club.
Let’s view these custom attributes in more detail:
set.seed(123)ggraph(karate_graph, layout ="fr")+# You can try different layout algorithms to see which one is more informativegeom_edge_link(alpha =0.5)+geom_node_point(size =10, color ="skyblue")+geom_node_text(aes(label =name), repel =TRUE)+theme_graph()+labs(title ="Friendship Network in Zachary's Karate Club", subtitle ="Who is friends with whom?")
What do you notice?
Can you spot any clusters of friends?
Are there members who seem to know everyone?
Do you see any potential dividing lines in the network?
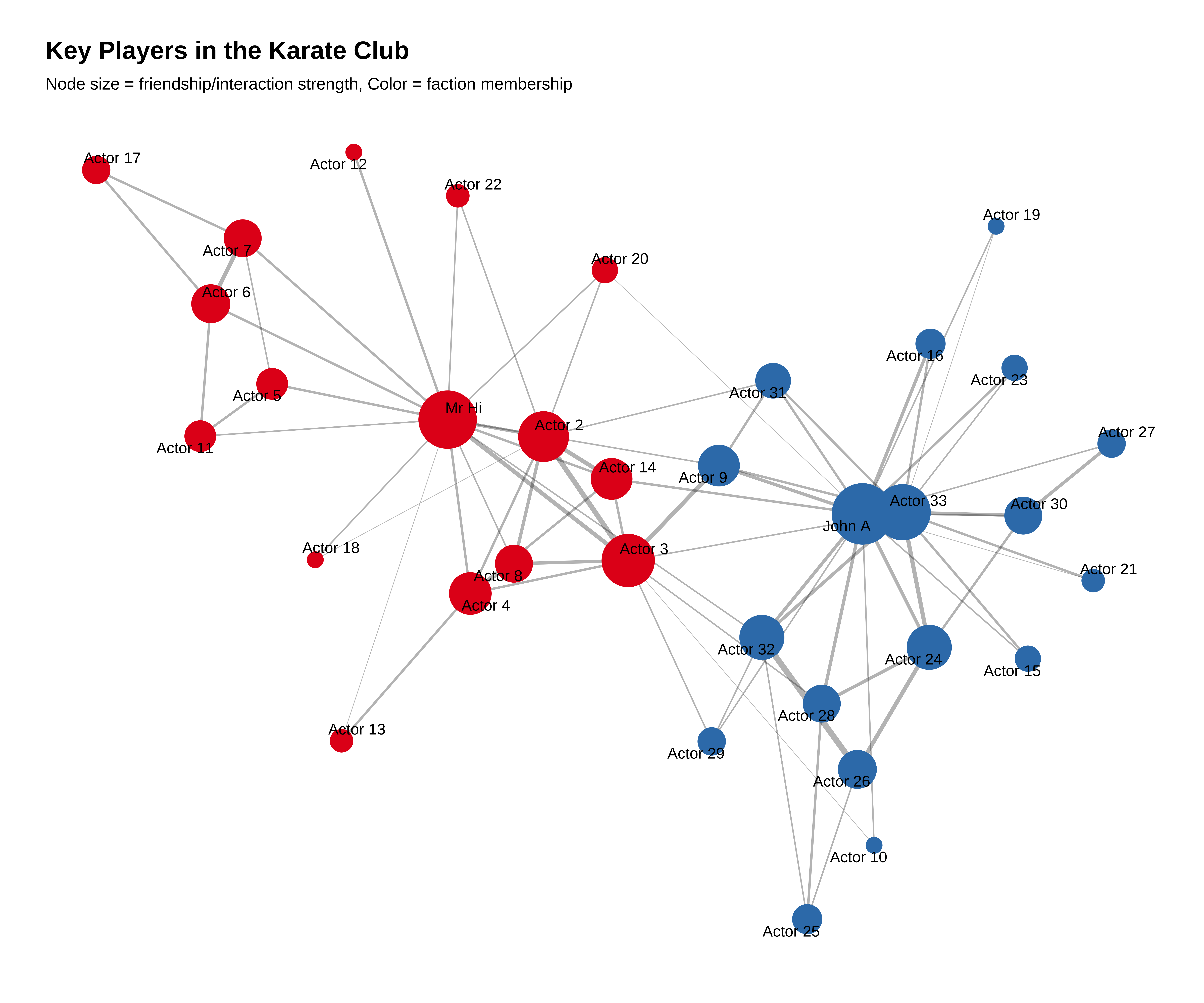
4.4 Step 2: Analyze Network Metrics
Let’s investigate who plays key roles in the club using our centrality measures.
# Calculate unweighted centrality measuresunweighted_analysis<-tibble( Member =V(karate_graph)$name, Faction =V(karate_graph)$Faction, Popular =degree(karate_graph), Bridge =betweenness(karate_graph), Central =closeness(karate_graph, normalized =TRUE), Influential =eigen_centrality(karate_graph)$vector)# Calculate weighted centrality measuresweighted_analysis<-tibble( Member =V(karate_graph)$name, Faction =V(karate_graph)$Faction, Popular =strength(karate_graph, weights =E(karate_graph)$weight), Bridge =betweenness(karate_graph, weights =E(karate_graph)$weight), Central =closeness(karate_graph, weights =E(karate_graph)$weight, normalized =TRUE), Influential =eigen_centrality(karate_graph, weights =E(karate_graph)$weight)$vector)# Combine and comparecomparison<-unweighted_analysis%>%rename_with(~paste0("Unweighted_", .), -c(Member, Faction))%>%inner_join(weighted_analysis%>%rename_with(~paste0("Weighted_", .), -c(Member, Faction)), by =c("Member", "Faction"))# Summarize average centrality of the two factions for both versionscomparison<-comparison%>%mutate(Faction =ifelse(Faction==1, "Mr. H's Faction", "John A.'s Faction"))%>%group_by(Faction)%>%summarize( Avg_Unweighted_Friends =mean(Unweighted_Popular), Avg_Weighted_Friends =mean(Weighted_Popular), Avg_Unweighted_Bridge =mean(Unweighted_Bridge), Avg_Weighted_Bridge =mean(Weighted_Bridge), Avg_Unweighted_Central =mean(Unweighted_Central), Avg_Weighted_Central =mean(Weighted_Central), Avg_Unweighted_Influential =mean(Unweighted_Influential), Avg_Weighted_Influential =mean(Weighted_Influential), Members =n())comparison
# A tibble: 2 × 10
Faction Avg_Unweighted_Friends Avg_Weighted_Friends Avg_Unweighted_Bridge
<chr> <dbl> <dbl> <dbl>
1 John A.'s F… 4.44 13.4 21.8
2 Mr. H's Fac… 4.75 13.8 31.1
# ℹ 6 more variables: Avg_Weighted_Bridge <dbl>, Avg_Unweighted_Central <dbl>,
# Avg_Weighted_Central <dbl>, Avg_Unweighted_Influential <dbl>,
# Avg_Weighted_Influential <dbl>, Members <int>
Understanding the Analysis
Individual Roles
Friendship Count (Degree): Shows who knows the most people in the club
Bridge Score (Betweenness): Identifies members who connect different social circles
Centrality Score (Closeness): Measures how well-positioned someone is to spread information
Faction Dynamics
Compare average metrics between Mr. Hi’s and John A.’s groups
Higher average friendship counts might indicate which group was more socially active
Bridge scores reveal which faction had more members connecting others (potentially across the faction)
4.5 Step 3: Visualize the Key Players
Now let’s create a more informative visualization that shows these roles: