Welcome to the world of topic modeling in Digital Humanities! In this chapter, we’ll explore how to identify latent topics in texts using computational methods.
Learning Objectives
📊 Understand core concepts of topic modeling
🛠️ Understand topic modeling with LDA
💻 Implement topic modeling with R
📈 Visualize topic distributions
1 Warming Up: Topic Identification Exercise 👥
Before diving into computational topic modeling, let’s explore something we do naturally every day: identifying themes and topics in text. When we read a newspaper, browse social media, or scan through emails, our brains automatically categorize content into topics based on words, context, and patterns.
But how do we actually do this? What clues do we use to determine if a text is about:
📰 Politics
⚽ Sports
💻 Technology
🎭 Entertainment
Understanding our own cognitive process of topic identification will help us grasp how machines approach this task.
Interactive Exercise
Let’s try a hands-on exercise with a short text from Jane Austen’s “Pride and Prejudice.” You’ll:
Read & Analyze: Identify the main topics in the text
Label: Input the top 1-3 topics you found
Select: Select words that support each topic
Rank: Order the importance of words within each topic
Why This Matters
This process mirrors what topic modeling algorithms do at a much larger scale. By experiencing the process first hand, you’ll better understand how machines can discover hidden thematic patterns across thousands of documents.
Topic Modeling Exercise
It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife. However little known the feelings or views of such a man may be on his first entering a neighbourhood, this truth is so well fixed in the minds of the surrounding families.
"My dear Mr. Bennet," said his lady to him one day, "have you heard that Netherfield Park is let at last? A gentleman of such wealth and consequence! To think of the prospects for our girls!"
Mr. Bennet replied that he had not, showing his usual indifference to his wife's enthusiasm for matchmaking and social advancement.
What main topics do you see in this text? (Enter 1-3 topics, enter the most important topic first)
Drag words into topic buckets. Words can belong to multiple topics!
Drag topics to reorder their importance (most important at top)
Drag words within each topic to rank them
Insights
When you completed the exercise above, you likely noticed several key aspects of topic identification that mirror how machines approach this task:
Word-Topic Relationships
Words can belong to multiple topics (e.g., “fortune” could relate to both “Wealth” and “Marriage”)
Some words are more strongly associated with certain topics than others
Context affects how we assign words to topics
Topic Distribution
Texts often contain multiple topics simultaneously
Topics aren’t evenly distributed - some are more dominant than others
The same word patterns can suggest different topics
Challenges in Topic Identification
Deciding the optimal number of topics
Dealing with ambiguous words
Balancing broad vs. specific topics
Handling overlapping themes
These observations align closely with how topic modeling algorithms work, particularly Latent Dirichlet Allocation (LDA), which we’ll explore next.
2 What is Topic Modeling? 📊
As we saw in our exercise, identifying topics in text requires recognizing patterns of words that frequently appear together. While humans can do this intuitively for a few documents, what if we needed to analyze hundreds or thousands of texts? This is where topic modeling comes in.
Key Concept
Topic modeling is a computational method that automatically discovers hidden thematic patterns, or “topics,” across a large collection of documents. Just as we identified themes in Pride and Prejudice by looking at word patterns, topic modeling algorithms find statistical patterns of word co-occurrence that suggest underlying themes.
Several algorithms have been developed for topic modeling, but Latent Dirichlet Allocation (LDA) has become the most widely used approach in Digital Humanities.
2.1 Key Assumptions of LDA
Like any algorithm, LDA has some key assumptions about how topics, documents, and words relate to each other.
Key Assumptions of LDA
Documents are Bags of Words
Word order doesn’t matter
Only the frequency of words is considered
Grammar and sentence structure are ignored
Topics are Word Distributions
Each topic is a probability distribution over words
Some words are more likely to appear in certain topics
Example: A “politics” topic might have high probabilities for “election,” “vote,” “democracy”
Documents are Topic Mixtures
Each document contains multiple topics in different proportions
Example: An article might be:
70% politics
20% economics
10% social issues
Topics are Generated First
The model assumes topics exist before documents
Documents are created by:
Choosing topic proportions
Selecting words from those topics
Combining words into documents
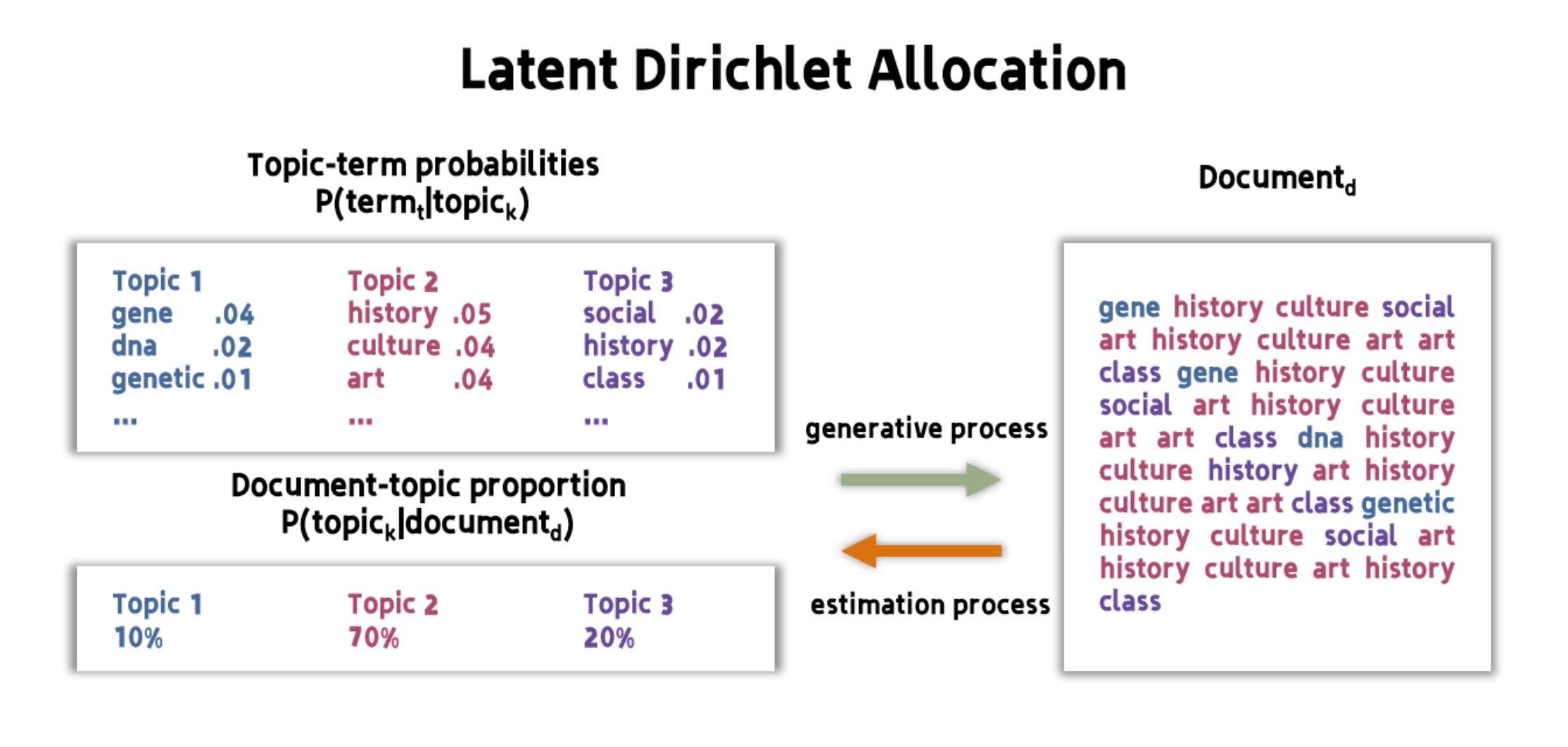
2.2 The Three Core Matrices
Now that we understand LDA’s assumptions, let’s explore how it represents and processes text data. At its heart, LDA works with three essential matrices that capture different aspects of the relationships between documents, topics, and words:
The Three Essential Matrices
Document-Term Matrix
Shows how words appear in documents
Like a spreadsheet counting word frequencies
Document-Topic Matrix
Shows how topics are distributed in documents
Tells us “this document is 70% politics, 30% economics”
Topic-Word Matrix
Shows which words are important for each topic
Reveals “these words are strongly associated with the politics topic”
Let’s examine each of these matrices in detail to understand how they work together to discover topics in our texts.
2.2.1 1. Document-Term Matrix
The starting point for topic modeling is converting our text collection into a format that computers can process efficiently.
What is a Document-Term Matrix?
A document-term matrix is a table where: - Each row represents a document - Each column represents a word - Each cell contains the frequency of that word in that document
For example, let’s look at how we might represent a small collection of book reviews:
Example Matrix
Document
romantic
secret
murder
love
detective
Review 1
5
1
0
4
0
Review 2
0
4
3
0
5
Review 3
2
3
2
1
2
Review 1 appears to be about a romance novel
Review 2 looks like a detective story
Review 3 might be a romantic mystery
Key Properties
Sparsity: Most cells contain zeros (most words don’t appear in most documents)
Size: For real collections, this matrix is usually very large
Information Loss: Word order and grammar are lost, but topic patterns remain
This matrix provides the foundation for discovering topics. LDA will use this to identify which words tend to appear together, suggesting underlying themes in our documents.
2.2.2 2. Document-Topic Matrix
This matrix represents how topics are distributed across documents.
Document-Topic Distribution
Each row shows how much of each topic appears in a document: - Rows = Documents - Columns = Topics - Values = Probability/proportion of each topic in the document
Example Matrix
Document
Romance
Mystery
Politics
Doc 1
0.7
0.2
0.1
Doc 2
0.1
0.8
0.1
Doc 3
0.4
0.4
0.2
Doc 1 is mostly about romance (70%)
Doc 2 is primarily a mystery (80%)
Doc 3 is an even mix of romance and mystery
2.2.3 3. Topic-Word Matrix
This matrix shows the distribution of words within each topic.
Topic-Word Distribution
Each row represents a topic’s probability distribution over words: - Rows = Topics - Columns = Words - Values = Probability of word appearing in topic
Example Matrix
Topic
love
mystery
murder
marriage
clue
Romance
0.30
0.05
0.01
0.25
0.01
Mystery
0.02
0.25
0.20
0.01
0.15
“love” and “marriage” are highly probable in the Romance topic
“mystery”, “murder”, and “clue” are more likely in the Mystery topic
Together, these three matrices capture the complex relationships between documents, topics, and words.
3 Implementing Topic Modeling with R 📊
Let’s analyze a dataset of potentially fake news articles using topic modeling. We’ll explore how different types of misinformation cluster into topics.
3.1 Fake News Dataset
For this topic modeling exercise, we’ll use a dataset of potentially fake news articles from Kaggle’s Fake News Detection Dataset. The fake news dataset contains more than 12,600 articles from different fake news outlet resources. Each article contains the following information: article title, text, type and the date the article was published on. To match the fake news data collected for kaggle.com, we focused mostly on collecting articles from 2016 to 2017. The data collected were cleaned and processed, however, the punctuations and mistakes that existed in the fake news were kept in the text.
The dataset includes:
News article titles
Full text content
Labels indicating article type (bias, conspiracy, etc.)
Language indicators
We’ll work with a subset of 500 English-language articles to keep our analysis manageable while still providing enough data to identify meaningful patterns.
Save it in the folder named data in your working directory (like we did for the dh_keywords.csv).
We can then load the csv file into RStudio:
library(pacman)p_load(tidyverse)# Load the dataset fake_news<-read_csv("data/fake_500.csv")
Rows: 500 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): title, text, type
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# A tibble: 6 × 3
title text type
<chr> <chr> <chr>
1 "Muslims BUSTED: They Stole Millions In Gov’t Benefits" "Pri… bias
2 "Re: Why Did Attorney General Loretta Lynch Plead The Fifth?" "Why… bias
3 "BREAKING: Weiner Cooperating With FBI On Hillary Email Investiga… "Red… bias
4 "PIN DROP SPEECH BY FATHER OF DAUGHTER Kidnapped And Killed By IS… "Ema… bias
5 "FANTASTIC! TRUMP'S 7 POINT PLAN To Reform Healthcare Begins With… "Ema… bias
6 "Hillary Goes Absolutely Berserk On Protester At Rally! (Video)" "Pri… bias
3.3 Text Preprocessing
Preprocessing Steps
Create unique document IDs
Generate n-grams (1-3 words)
Remove stopwords
Filter rare terms (n = 1)
# Load required packagesp_load(tidytext, topicmodels, # For LDALDAvis, # For interactive visualizationstringr, stopwords)# Create document-term matrixnews_dtm<-fake_news%>%mutate(doc_id =row_number())%>%unnest_tokens(word, text, token ="ngrams", n_min =1, n =3, stopwords =c(stopwords::stopwords("en"),stopwords::stopwords(source ="smart")))%>%count(doc_id, word)%>%filter(n>1)%>%cast_dtm(doc_id, word, n)news_dtm
<<DocumentTermMatrix (documents: 382, terms: 10441)>>
Non-/sparse entries: 21711/3966751
Sparsity : 99%
Maximal term length: 34
Weighting : term frequency (tf)
3.4 Fitting the LDA Model
3.4.1 Choosing the Number of Topics
What is k?
In topic modeling, ‘k’ is the number of topics you want the model to find.
If k = 3, you’re asking the model to find 3 topics in the data
If k = 10, you’re looking for 10 different topics
This is one of the most important decisions you’ll make when topic modeling!
Now, how do we choose k for our fake news dataset? We are in luck because we have “external help” in our dataset, which is the type varaible (tags of the type of news articles).
# Check unique types in our datasetfake_news%>%count(type)
# A tibble: 4 × 2
type n
<chr> <int>
1 bias 53
2 bs 308
3 conspiracy 124
4 fake 15
Why Start with k = 4 for Our Analysis? 📊
In this dataset, we have a helpful guide:
Our articles are already labeled with 4 different types
These types represent different categories of fake news
This suggests that k = 4 might be a good starting point
Important Caveat About Topics vs Types ⚠️
Remember: The model’s topics might not match our human-labeled types!
Types = Human-assigned categories (like “bias” or “conspiracy”)
Topics = Patterns the model finds in the actual words used
Why they might be different:
The model looks at word patterns, not human judgments
An article labeled as “bias” might use similar language to “conspiracy”
There might be hidden patterns we humans didn’t notice
The same type of fake news might use different writing styles
Think of it like this: We’re giving the model a hint to look for 4 patterns, but it might find different groupings than our human labels suggest!
Important Caveats ⚠️
In Real Life: You usually won’t have pre-labeled categories
No Perfect k: There’s rarely one “right” number of topics
Different Patterns: The model might find different groupings than human labels
Iterative Process: You usually need to try several values of k and use your own judgement to determine which is the optimal number of k
Based on this understanding, let’s create our topic model with k = 4:
# Set global seed for reproducibilityset.seed(1234)# Create our topic modellda_model<-LDA(news_dtm, k =4, # Number of topics to find method ="Gibbs", control =list( seed =1234, # For reproducible results iter =2000, # Number of iterations thin =100, # Save every n iteration best =TRUE, # Return the best model verbose =FALSE# Switch on to show progress and monitor convergence))
Why Use Gibbs Sampling? 🎲
Think of Gibbs sampling like exploring a city to find the best restaurants:
More Thorough Exploration 🗺️
Instead of stopping at the first good restaurant you find (like simpler methods do)
Gibbs sampling keeps exploring to find even better options
Better with Uncertainty 🤔
Words often have multiple meanings
Gibbs sampling is good at handling this ambiguity in texts
More Reliable Results ✅
Less likely to get stuck in one interpretation
Keeps looking for better ways to group topics
Good for Humanities Texts 📚
Works well with complex, nuanced writing
Handles the way words change meaning in different contexts
The parameters tell it:
How many times to explore (iter = 1000)
How often to take notes (thin = 100)
Where to start looking (seed = 1234)
3.5 LDA Results Can Vary Between Runs 🎲
Random Starting Points
Each word in each document starts with a random topic assignment
Different starting points can lead to different final configurations
Probability-Based Sampling
The algorithm (Gibbs sampling) randomly samples new topic assignments based on probabilities
While it converges towards good solutions, the path can vary
Multiple Valid Solutions
Different runs may find different but equally valid topic configurations
Especially true for complex, overlapping topics in natural language
Best Practice:
Always set a seed for reproducibility
Run multiple times with different seeds to assess stability
Consider using consensus methods for more robust results
sessionInfo()# Record R version, OS, and package versions
Use Fixed Seeds in Parallel Processing
library(parallel)RNGkind("L'Ecuyer-CMRG")# For parallel-safe random numbers
Consider Using a Reproducible Pipeline
Use renv for package management
Docker containers for complete environment control
Document all random seed values used
3.6 Exploring Results
Key Parameters/Results in Topic Modeling 📊
Beta (β) or Phi (φ) Values: Topic-Word Probabilities 📝
What it is: How strongly each word belongs to each topic
Also called: φ (phi) in technical documents and code
Think of it like: A recipe showing how much of each ingredient (word) goes into each dish (topic)
Example: In a “sports” topic, words like “game” might have high β values
Gamma (γ) or Theta (θ) Values: Document-Topic Probabilities 📚
What it is: How much each document belongs to each topic
Also called: θ (theta) in technical documents and code
Think of it like: A pie chart showing what percentage of each topic is in a document
Example: An article might be 70% politics and 30% economics
Why Two Names?
β (beta) and γ (gamma) are commonly used in explanations
φ (phi) and θ (theta) are often used in technical papers and code
They mean the same thing - just different notation conventions!
You’ll see phi and theta in our code, but they’re the same as β and γ
Let’s look at these values in our model:
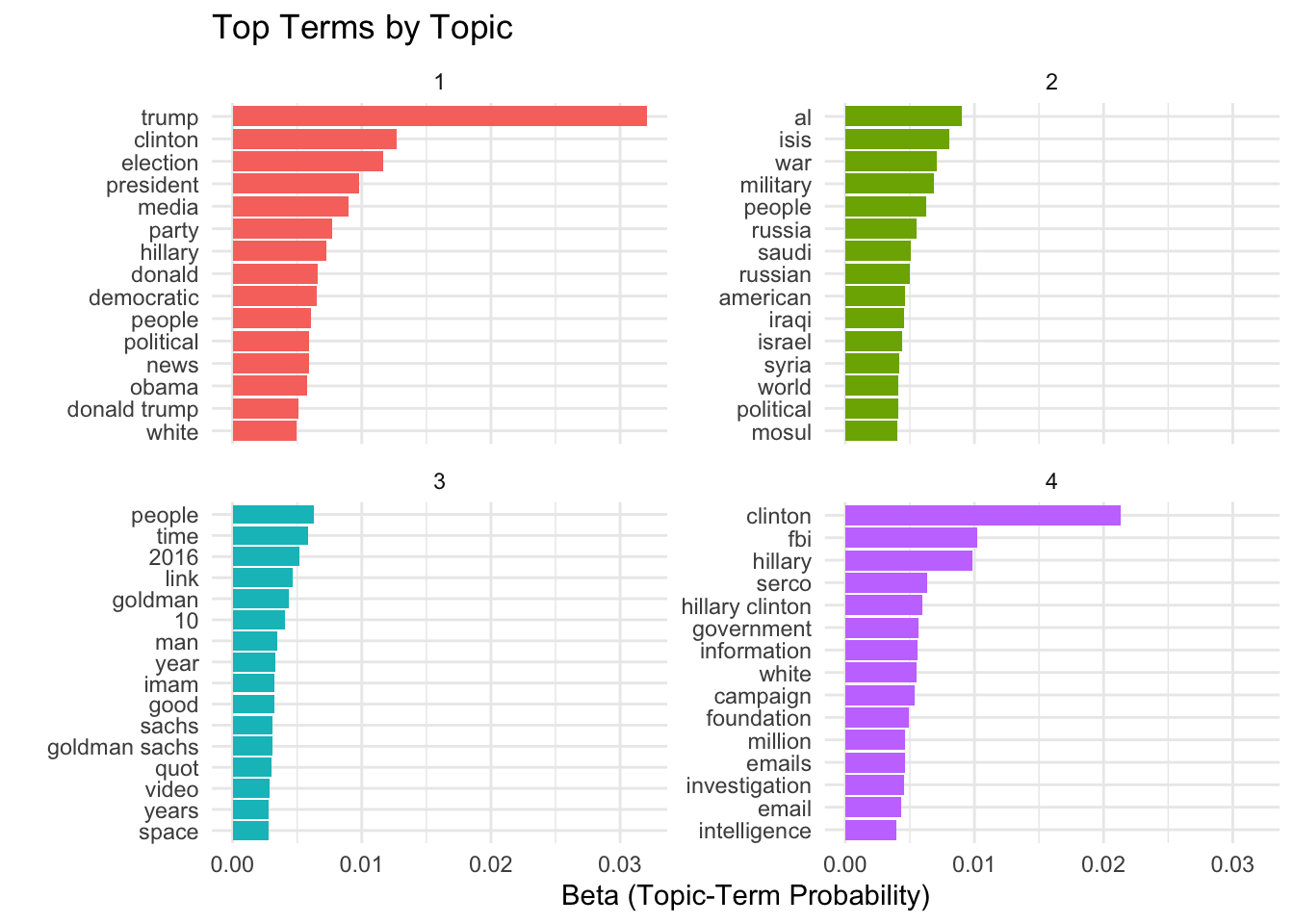
# Extract top terms per topictop_terms<-tidy(lda_model, matrix ="beta")%>%group_by(topic)%>%slice_max(beta, n =15)%>%ungroup()# Visualize top termsggplot(top_terms)+geom_col(aes(beta, reorder_within(term, beta, topic), fill =factor(topic)))+facet_wrap(~topic, scales ="free_y")+scale_y_reordered()+theme_minimal()+theme(legend.position ="none")+labs( title ="Top Terms by Topic", x ="Beta (Topic-Term Probability)", y ="")
3.7 Document-Topic Distribution
Let’s see how articles are distributed across topics:
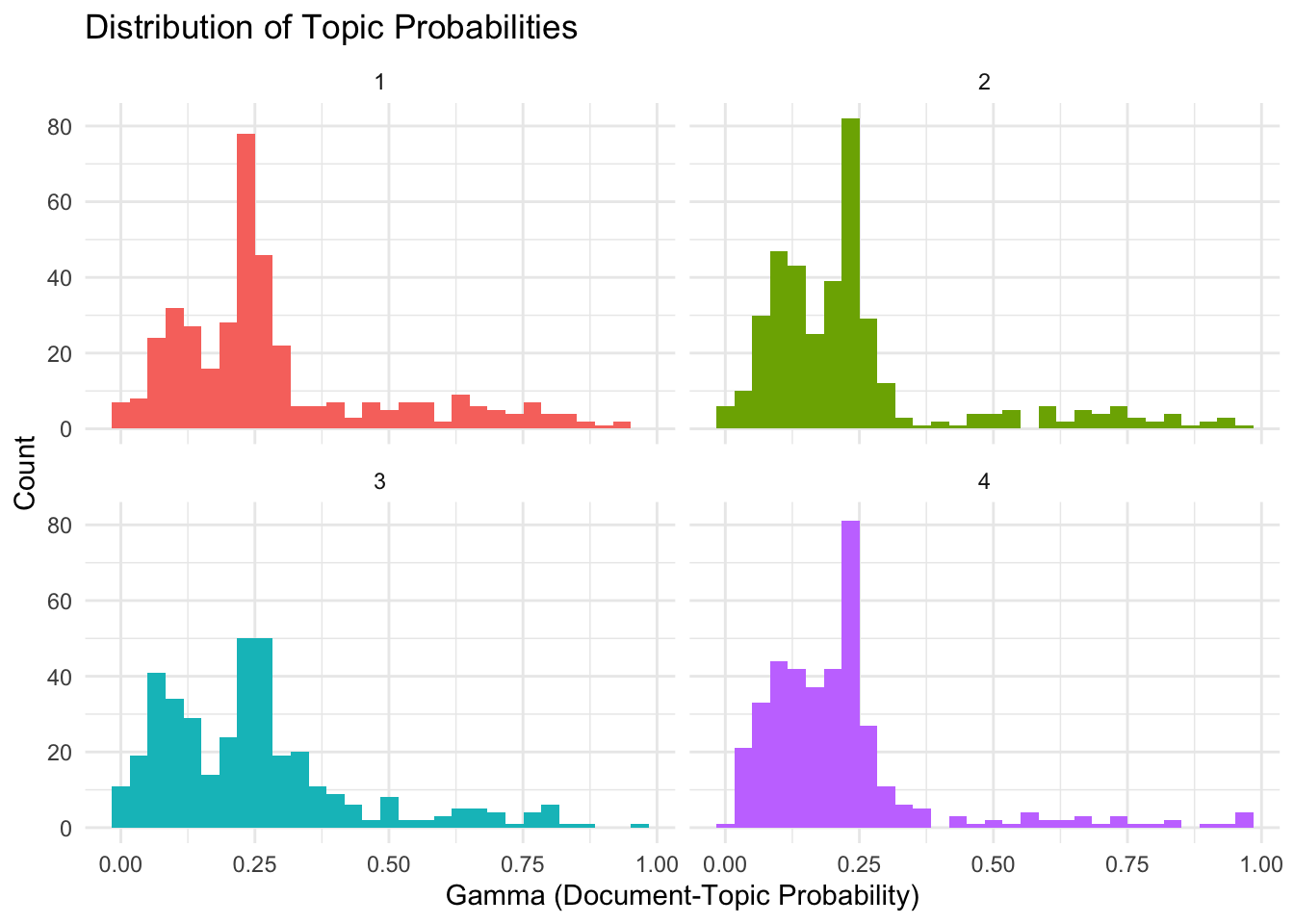
# Extract document-topic probabilitiesdoc_topics<-tidy(lda_model, matrix ="gamma")%>%mutate(title =fake_news$title[as.numeric(document)])# Plot distributionggplot(doc_topics)+geom_histogram(aes(gamma, fill =factor(topic)), bins =30)+facet_wrap(~topic)+theme_minimal()+theme(legend.position ="none")+labs( title ="Distribution of Topic Probabilities", x ="Gamma (Document-Topic Probability)", y ="Count", fill ="Topic")
3.8 Interactive Visualization with LDAvis
# Prepare data for LDAvisdtm_matrix<-as.matrix(news_dtm)# Get document lengths and term frequenciesdoc_lengths<-rowSums(dtm_matrix)term_freqs<-colSums(dtm_matrix)# Create the JSON objectjson<-createJSON( phi =posterior(lda_model)$terms, # topic-term distributions theta =posterior(lda_model)$topics, # document-topic distributions doc.length =doc_lengths, # document lengths vocab =colnames(dtm_matrix), # terms term.frequency =term_freqs# overall term frequencies)# Create interactive visualizationserVis(json)
Loading required namespace: servr
Understanding the Visualization 🎨
LDAvis shows us:
Left side: Bubbles representing topics
Size = how common the topic is
Distance = how similar topics are to each other
Right side: Most relevant words for selected topic
Red bars = word frequency in topic
Blue bars = word frequency in entire dataset
Understanding LDAvis Lambda (λ) 🎚️
The lambda slider in LDAvis helps you explore word relevance in topics:
What is Lambda (λ)?
A number between 0 and 1
Controls how we rank words in topics
Helps balance between two ways of measuring word importance
How Lambda Works
λ = 1.0: Shows common words in the topic
λ = 0.0: Shows unique/exclusive words to the topic
λ = 0.6: Default balance between common and unique (Sievert & Shirley, 2014)
Think of it Like This
High λ (near 1): “What words appear most in this topic?”
Low λ (near 0): “What words are special to this topic?”
Middle λ: “What words are both common AND special?”
3.9 Finding the Most Representative Texts for Each Topic
Let’s find which articles best represent each topic we discovered:
# Get document-topic probabilitiesdoc_topics<-posterior(lda_model)$topics# Create dataframe with cleaned column namesdoc_topics_df<-as.data.frame(doc_topics)%>%# Rename columns to be more descriptiverename_with(~paste0("Topic_", .), everything())%>%mutate(doc_id =row_number())%>%left_join(fake_news%>%mutate(doc_id =row_number())%>%select(doc_id, title, text, type), by ="doc_id")# Find representative documentsrepresentative_docs<-doc_topics_df%>%pivot_longer( cols =starts_with("Topic_"), names_to ="topic", values_to ="probability")%>%group_by(topic)%>%slice_max(probability, n =3)%>%arrange(topic, desc(probability))# Display results with more contextrepresentative_docs%>%select(topic, title, type, probability)%>%arrange(topic, desc(probability))%>%knitr::kable( caption ="Most Representative Articles for Each Topic", digits =3)
Most Representative Articles for Each Topic
topic
title
type
probability
Topic_1
Mike Pences Plane Slides off Runway at LaGuardia
bs
0.950
Topic_1
Oregon Standoff Leaders Acquitted For Malheur Wildlife Refuge Takeover
bs
0.932
Topic_1
‘COLOR REV’ AGIT PROP: George Soros MoveOn Agitators March on America – as Billionaire Instigator Sued
conspiracy
0.900
Topic_2
DONALD J. TRUMP - Officially Lays Out His NEW DEAL FOR BLACK AMERICA.
bs
0.959
Topic_2
Tree-Shaped Vertical Farm Can Grow 24 Acres Of Crops
conspiracy
0.937
Topic_2
The U.S./Turkey Plan For “Seizing, Holding, And Occupying” Syrian Territory In Raqqa
conspiracy
0.922
Topic_3
Julian Assange Surfaces - Speaks at Argentina Conference Via Telephone
bs
0.955
Topic_3
Smart Meter Case Testimony Before the Pennsylvania Public Utility Commission: What No One Wants to Acknowledge About EMF Damage (Part 4 of 4)
conspiracy
0.879
Topic_3
New NASA Footage Films UFO Flying Past
bs
0.848
Topic_4
NA
bs
0.974
Topic_4
Hell Comes to Frogtown: Alt Right and Triumph of Transhumanism
conspiracy
0.974
Topic_4
NA
bs
0.970
Analysis Tips 🔍
When examining representative texts:
Read the full text of top documents
Look for common themes
Compare with topic words
Consider why these particular texts are representative
Note any surprising patterns
Model Quality Checks 🔍
Check Preprocessing Issues
Look for remaining stopwords in topics
Check for non-meaningful n-grams
Verify document lengths after filtering
Examine if important domain terms were removed
Evaluate Topic Coherence
Do words in each topic make sense together?
Are there topics that seem too general?
Are there redundant topics?
Check if topics are well-separated
Evaluate quantitative metrics (e.g., coherence score, though these are not necessarily related to human interpretation)
Document-Topic Distribution
Are there documents with no clear topic assignment?
Are some topics dominating too many documents?
Check if document types cluster as expected
Look for outlier documents
Common Red Flags
Topics dominated by numbers or punctuation
Very similar word distributions across topics
Many documents with equal probability across all topics
Topics that don’t align with domain knowledge
Potential Solutions
Adjust preprocessing (stopwords, n-grams)
Try different numbers of topics (k)
Modify model parameters (α, β)
Consider document length normalization
Remove very short or very long documents
3.10 Hands-On Coding 💻
👥 Group Exercise: Finding the Optimal Topic Model
Setup
Form groups of 3-4 students
Each group member chooses a different k value:
Student 1: k = 3
Student 2: k = 5
Student 3: k = 7
Student 4: k = 9 (if fourth member)
Take notes on:
Topic coherence (are words in each topic related?)
Topic separation (how distinct are the topics?)
Topic interpretability (can you name each topic?)
Coverage (are important themes missing?)
Group Discussion
Compare your models using this template:
k value
Pros
Cons
Notable Topics
Missing Themes
k = 3
k = 5
k = 7
k = 9
Discussion points:
🎯 Which k value provides the most useful insights for fake news analysis?
📊 How do the topic visualizations change as k increases?
🤔 What tradeoffs do you notice between:
Simplicity vs. detail?
Coherence vs. coverage?
Interpretability vs. granularity?
Group Recommendation
Prepare a brief recommendation:
Which k value would you choose?
What are your top 3 reasons?
What are the limitations of your choice?
Class Share
Each group shares their recommended k value and reasoning with the class. Compare how different groups approached the decision!
4 Learning Check 🏁
1. What is the main purpose of topic modeling?
2. In LDA, what does 'k' represent?
3. What is a key assumption of LDA?
4. When exploring topics in LDAvis, what do the bubbles represent?
5. Why might topic modeling results differ from human-assigned categories?
5 Conclusion
Key Takeaways
In this chapter, we’ve covered:
Understanding the basics of topic modeling and LDA
Implementing topic models with R
Visualizing topics using LDAvis
Interpreting and evaluating topic modeling results
Applying topic modeling to fake news analysis
Our analysis of the fake news dataset demonstrates how topic modeling can reveal hidden patterns in text collections. Through both computational analysis and human interpretation, we’ve explored how different types of misinformation cluster into topics. The interactive visualizations allow us to explore these patterns dynamically, highlighting both the strengths and limitations of topic modeling tools.
Remember that topic models are exploratory tools that complement, rather than replace, careful reading and analysis. The patterns we’ve discovered should spark questions and encourage deeper investigation of the texts, rather than being treated as definitive conclusions.